The acquisitions of MosaicML and Neeva by Databricks and Snowflake prompted this blog. Some definitions and then lets zoom out..
Consumer AI: heypi.com, ChatGPT and Bard are consumer AI service
Enterprise AI: Any SaaS/SW product powered by neural nets that is addressing a workplace/B2B or B2C use case. e.g. Jasper.ai, Databricks, Snowflake.
We all have seen and heard about this.

From Nov’22 to now Aug’23 – in one human pregnancy cycle (9 months), technology companies have given birth to their new child(ren) – ChatGPT, Bard, LLaMa-1,2, Dolly and many more LLMs (open & closed models with the recent announcement of Inflection (www.heypi.com) raising $1.3B, the consumer AI is in full swing. Combined they have raised >$10B.

Reflecting back to the 2000s, the consumer use cases emerged first, followed by enterprise. Search (Google), e-commerce (Amazon), and social media (Yahoo, MySpace) were the precursors to the rise of enterprise SaaS (CRM via Salesforce as the initial one). While Salesforce (founded in February 1999) was a cloud-first company, the “SaaSification” or “cloudification” of enterprises did not happen until AWS S3 and EC2 were announced in 2007 — almost 8 years later. To be clear Salesforce was not a cloud-native or cloud-resident SaaS until the past few years. It had SaaS as a business model from day 1. To get some data on Enterprise vs Consumer, I turned to our new Oracles…ChatGPT and Bard.
I asked ChatGPT & Bard the following prompts. ChatGPT failed, but bard came through..
- What is the total accumulated revenue for consumer SaaS?
- What is the total accumulate revenue for enterprise SaaS? (it gave market TAM instead)
- What is the total VC investments in consumer SaaS between 2003 and 2022?
- What is total COGS for consumer SAAS companies between 2003 and 2022?
- What is the total COGS for enterprise SaaS companies between 2003 and 2022?
- What is the accumulated revenue of AWS, GCP and Azure between 2007 and 2022?
- Can you now summarize the above data – into Enterprise SaaS and Consumer SaaS by revenue, COGS and investments between 2003 and 20022 in a simple table? – It put then summary in Google sheets.
| Metric | Enterprise SaaS | Consumer SaaS | Source Data |
| Market TAM (2021) | $128.5 billion | $113.1 billion | Gartner |
| COGS (2003-2022) | $483.1 billion | $359.3 billion | Statistia |
| VC investments (2003-2022) | $330.3 billion | $243.8 billion | Pitchbook |
| Top 5 companies by revenue (2022) | Salesforce, Workday, ServiceNow, Adobe, Microsoft | Zoom, Slack, Atlassian, Adobe, Microsoft | |
| Top 5 companies by COGS (2022) | Salesforce, Workday, ServiceNow, Adobe, Microsoft | Zoom, Slack, Atlassian, Adobe, Microsoft | |
| Top 5 companies by VC investments (2022) | Salesforce, Workday, ServiceNow, Adobe, Microsoft | Zoom, Slack, Atlassian, Adobe, Microsoft |
| Cloud Platform | Accumulated Revenue (2007-2022) |
| AWS | $900 billion |
| Azure | $350 billion |
| GCP | $150 billion |
A few observations with this high level perhaps inconsistent sources of data.
- A significant portion of the $800B in COGSs was funded by Venture investments (spurious correlation – the total VC investments is also close to $570B).
- While the data here shows enterprise SaaS is bigger than consumer SaaS, if you include FB, GOOG, AWS – consumer SaaS is a lot bigger but also lot more concentrated vs enterprise SaaS where there are 150+ public companies and perhaps hundreds of startups.
- AWS was the biggest beneficiary of both the VC investment dollars and the open source community (AWS resold open source compute cycle for many years)
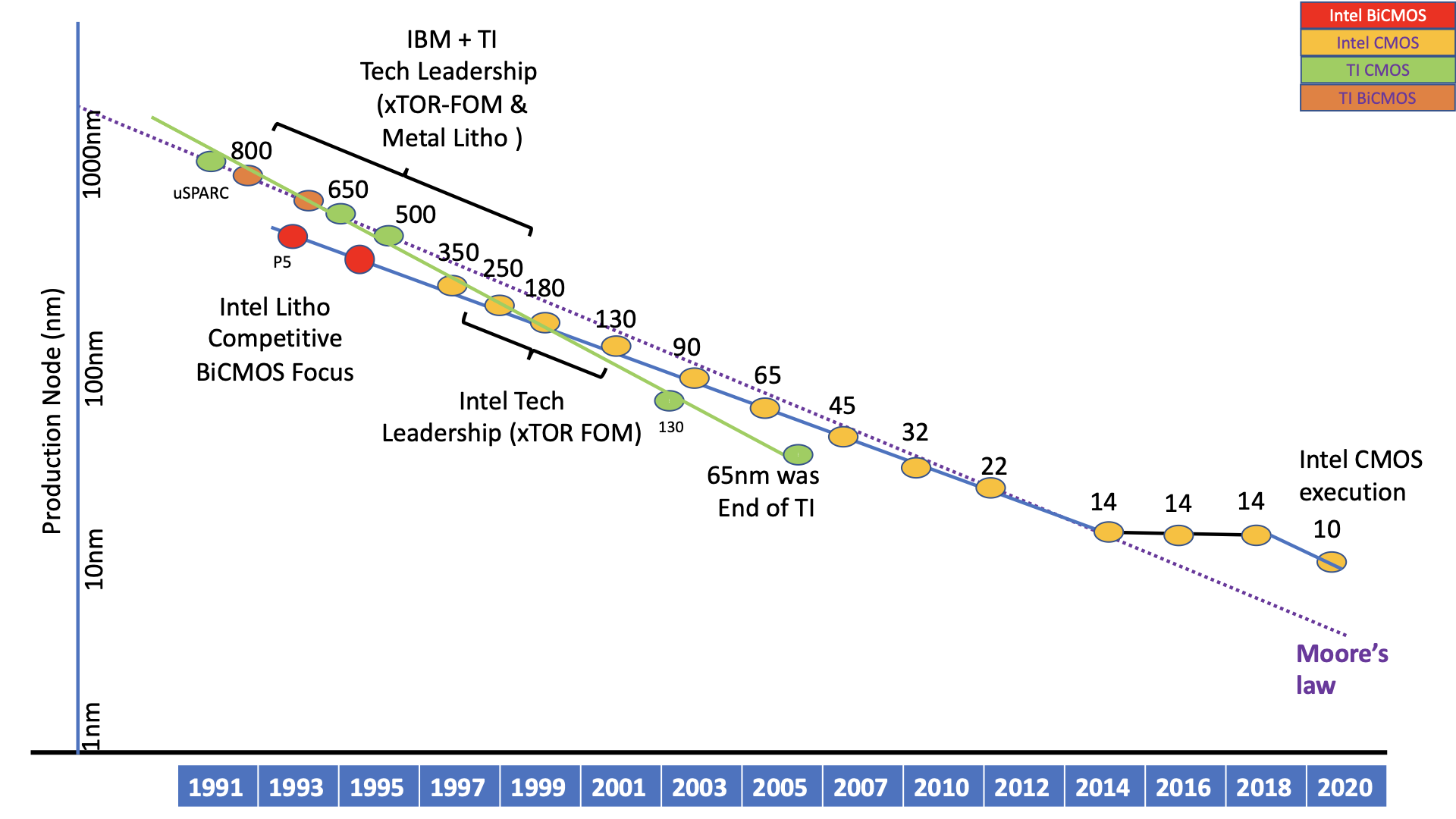
- Salesforce (CRM) was early with enterprise SaaS in 1999 along with Google and Amazon (consumer SaaS), the enterprise SaaS business inflection happened around circa 2007 i.e. the knee of the curve was 2007 – a 7-8 year lag behind consumer SaaS. (Salesforce revenue as a proxy).
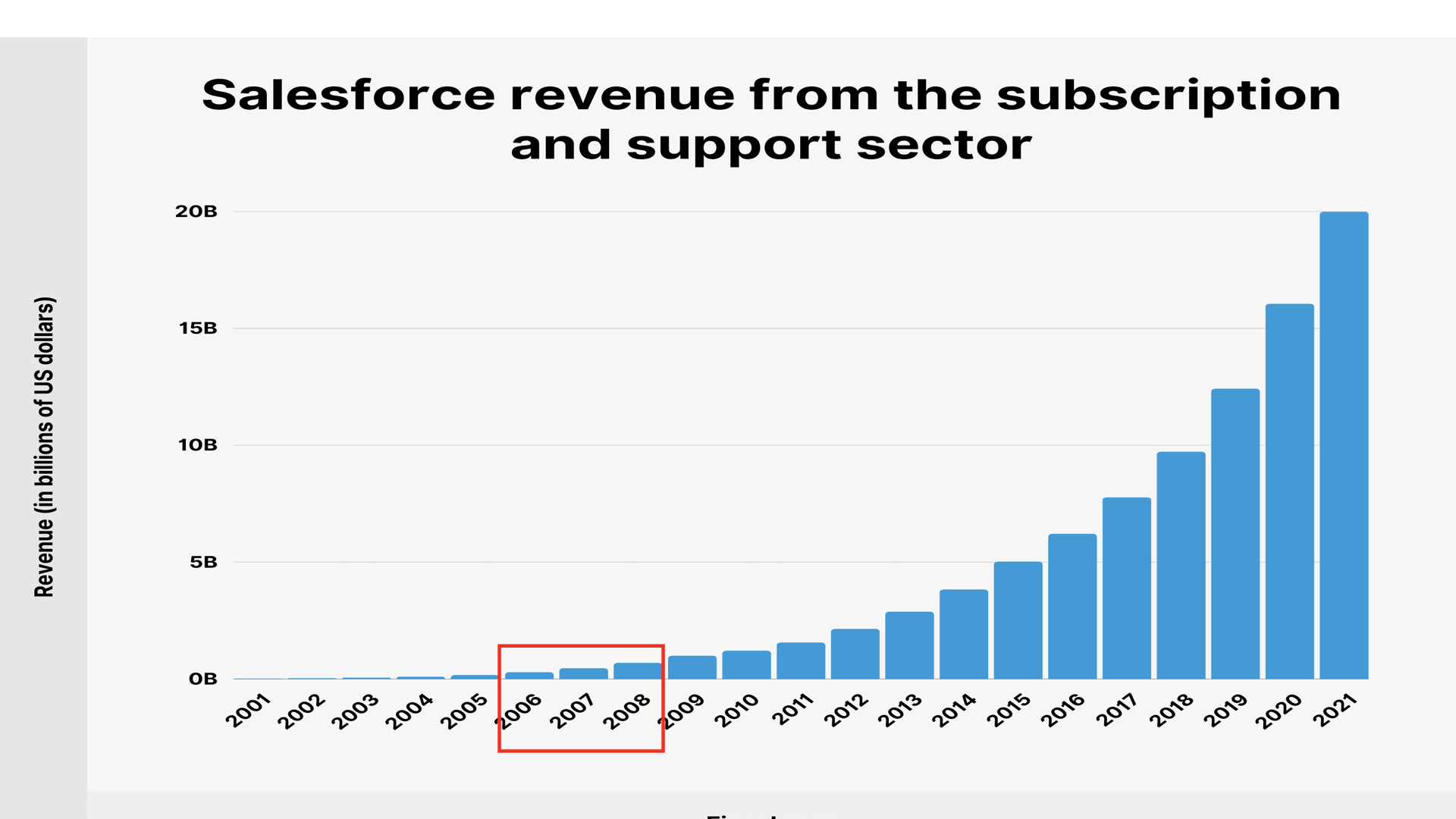
A significant portion of the $800B of VC investments were funding CACC (Cost of Customer Acquisition). While I don’t have the actual percentage spent on CACC, but I would hazard a guess it would have been >30% maybe as high as 50% for many companies.
Assuming conservative 20%, that is $100B of venture capital going into CACC. And perhaps >$500B of cloud spend (COGS) with AWS, GCP and Azure during the same years. The total revenue of AWS, GCP and Azure between 2007 and 2022 is $1.4 trillion.
Hindsight is 20/20 – but projecting forward consumer AI and enterprise AI are going to be bigger – but the big shift is now from cost of customer acquisition (CACC) to Cost. of Compute (CoC) and the time collapse between Consumer AI and Enterprise AI. Lets look at both perhaps speculate or project forward.
- Cost of Compute (CoC)
A significant portion of VC and Corporate investments in the past 9 months is for cost of compute for largely consumer AI companies. The winner (to-date) in this round is Nvidia like SUNW was in the last round until 2003. Back in 2001, Internet was run by Sun boxes until the Open source, Linux and distributed systems became the new infrastructure stack.
As Elad Gil points out on twitter “At this point LPs in venture funds should just wire money direct to NVIDIA & skip the LP->VC->Startup->NVIDIA step”. Not so fast – the fish was falling into the boat back in 2001 at Sun and soon after it had to go fishing. More on this later.
And then there is Martin’s tweet – “If a company is going to train a $5B model, wouldn’t it make sense to use 5% of that to build a custom ASIC for that model? The benefits are certain to dwarf the 5% investment. At these scales, even ASIC design costs become marginal“. 5%. of $10B – enough for a new systems company to be built either from within the traitorous 8 or via a VC / Corporate investment. (more on this in a future blog).
The wake of the SaaS tsunami (since 2001) left us with AWS as the winner and leaving behind big SMP OEMs like SUNW, SGI, DEC, IBM). 20 years later the traditional Enterprise is served by 3 OEMs (CSCO, Dell, HPE) and 2+ enterprise software companies (Oracle, SAP and a distant third in IBM). Now they (the traditional enterprise infrastructure companies – both hardware and software) face a new tsunami with AI. A multi-trillion COGS spend is ahead of us and as we see new cloud investments (Coreweave, LambdaLabs) as well as AI+SaaS companies (the list above), potentially becoming the new AWS or GCP as they grow. Nvidia is spreading its new found shareholder capital to blanket this space. The silicon guys have woken up as they control the other end of the IP/value chain in a cloud stack. Given $10B+ of venture and corporate $s have gone to spend CoC in the past 7 months, it makes sense to fund startups that addresses CoC and challenge the incumbents? Seems like time is now – AWS from a perception has gone from #1 to #3 player in AI compute overnight, with Nvidia and (and perhaps its compatriots) thinking of how to enter this space.
AI unlike the past two decades of SaaS wants to be everywhere. In the cloud, on-prem, in-between, edge etc etc.
2. Enterprise AI
It took 7 years between 2000 and 2007 and >$10+B investments to transform the Enterprise SaaS with a new set of players. Instead of 7 years, in 7 months, we move from Consumer AI to Enterprise AI at breakneck speed. With the acquisition of Neeva by Snowflake, and MosaicML by Databricks, the first set of rockets have been launched to take on traditional enterprise companies (SAP, Oracle, IBM).
Back in 2007, the winners for infrastructure were new cloud companies. This time the winners for new infrastructure is likely to include silicon players (e.g. Nvidia, Intel, AMD, AVGO) and potentially some losers. Unlike 2007, with AI, there is this issue of Data (sovereignty, privacy, security) and CoC. Enterprise SaaS (e.g. Salesforce) started with on-prem infrastructure but moved to the cloud eventually. But there is a real possibility of reverse migration (move closer to data) especially with AI. Snowflake is already positioning itself as the DATAI cloud.
What is becoming a possibility is for the first time in perhaps 40-50 years, the incumbent enterprise software infrastructure companies (SAP and Oracle) are going to be challenged by Databricks and Snowflake. I say respectively because SAP is to Databricks and Oracle if to Snowflake follow Jerry Chen’s framework ( systems of intelligence and systems of record ) and it applies here once more.
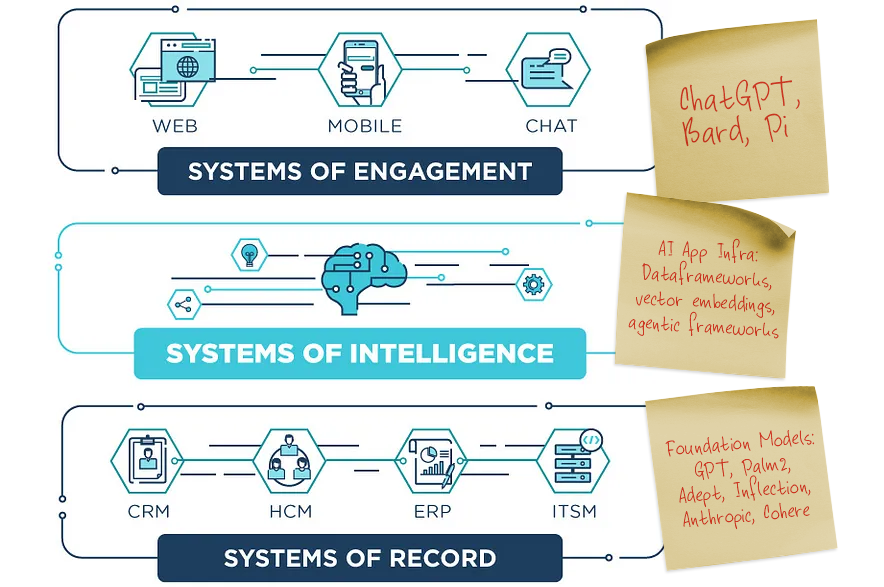
The systems of engagement are the new Chat Bots like ChatGPT and Bard. In the 1990s client server era – SAP took pole position in the App Tier (“Systems of Intelligence”) while Oracle powered the enterprises (“Systems of Record”) with Sun, HP and IBM being the infrastructure providers. I had a front row seat between 1991 and 2001 (Sun, SPARC etc) in both being enablers for SAP and Oracle via SMP platforms and built the multi-core/threaded processors to match with the emerging AppTier built with Java as the programming layer to take advantage of the thread parallelism from the silicon world.
With onset of AI, the agility and pace with which Databricks and Snowflake are Co-opting AI (both are in the cloud today) can challenge the traditional Enterprise duo (SAP and Oracle). While they both think they are competing, they are actually offering different value to the enterprises and over time they will overlap, but not today. The bigger opportunity for both is not to compete with each other but use the new tool in the quiver (“GenAI”) to upend SAP and Oracle with sheer velocity of execution, engagement value (SQL vs natural language. Both have to address data sovereignty if they want to take their fight to the SAP and Oracle world. Addressing that means like enterprise SaaS jumped to the cloud back in 2007, enterprise AI ha to extend from the cloud to be closer to the customer.
The success of Snowflake and Databricks despite competing and layering on top of current cloud infrastructure is proof point that they can compete against well capitalized and tooled companies (AWS – Redshift/EMR and Google – Spanner/BigQuery….) that if they chose to extend their offerings to on-prem enterprises , they can win if they can address the data problem i.e. they need to jump from current cloud to emerging new cloud offerings. They can enable and consume new infrastructure players who can solve or address the data proximity issue.
Given the scale of COGS spend in the cloud for $1.4 Trillion, there is a atleast a $1Trillion of spend ahead of us in Enterprise AI away from the big three (AWS, GCP, Azure) in the next 15 years potentially led by the new duo of Databricks and Snowflake. On-prem Enterprise AI – which will continue to thrive and could well seed the new infrastructure players.
Lets revisit this in 3 years if new infrastructure providers emerge addressing CoC in new and differentiated ways.